- Published on
Fault tolerant search with Elasticsearch
Fault tolerant search with Elasticsearch - results even with typing errors
This blog entry is on the topic of fault tolerance in search engines. Fault tolerance is not meant here as high availability of the Elasticsearch server. It is about the ability of a search engine like Elasticsearch to return relevant results even if the user's query contains typographical errors or misspellings. We'll be discussing how Elasticsearch can use tokenization to allow a tolerance of spelling mistakes.
What is fault tolerance in search engines
Fault tolerance in search queries refers to the ability of a search engine like Elasticsearch to return relevant results even if the user's query contains typographical errors or misspellings. Complicated technical terms or foreign words are sometimes misspelled. In such cases, the search engine should react in an fault-tolerant manner.
There are a few different methods that search engines can use to achieve fault tolerance in user queries:
- Spell checking: Search engines can use spell-checking algorithms to automatically correct common spelling errors and typos in a user's query.
- Tokenization: Search engines can break a text down into smaller chunks, called tokens. In most cases, these tokens are individual words, such as "New York" into "New" and "York".
- Stemming: Search engines can use stemming algorithms to match variations of a word based on its root or stem, such as "search" and "searched."
- Synonym matching: Search engines can match queries to synonyms of the original word, such as "car" and "automobile"
- Machine Learning : Search engines can use Machine Learning Algorithms to improve ranking and relevance of the results by learning the patterns of user's query and the search behavior.
By using these methods, search engines can return relevant results even if the user's query is not perfectly formulated, making the search experience more user-friendly and efficient.
In this post, we'll be discussing how search engines use tokenization to understand and process user queries. Tokenization is the process of breaking down a user's query into individual words, phrases, and symbols, and is a crucial step in natural language processing (NLP) for search engines. By tokenizing a query, search engines can better understand the intent of the user and match it with relevant results. We'll explore the different methods of tokenization that are used by search engines, and how they help improve the accuracy and relevance of search results.
Elasticsearch Analyzer and Tokenizer
Analyzer
Text analysis enables Elasticsearch to perform full-text search, where the search returns all relevant results rather than just exact matches. You can create your custom analyzer
Tokenizer
Analysis makes full-text search possible through tokenization: breaking a text down into smaller chunks, called tokens. In most cases, these tokens are individual words.
N-gram tokenizer for Velociraptor
- Ve, el, lo, oc, ci, ir, ra, ap, pt, to, or (bigram, 2-gram)
- Vel, elo, loc, oci, cir, ira, rap, apt, pto, tor (trigram, 3-gram)
PUT /dinosaurs
{
"settings": {
"analysis": {
"analyzer": {
"2_3_ngram_analyzer": {
"type": "custom",
"filter": "lowercase",
"tokenizer": "2_3_ngram_tokenizer"
}
},
"tokenizer": {
"2_3_ngram_tokenizer": {
"token_chars": [
"letter",
"digit",
"punctuation",
"symbol",
"whitespace"
],
"min_gram": "2",
"type": "ngram",
"max_gram": "3"
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "2_3_ngram_analyzer"
}
}
}
}
Now the search will work with wrong spelling.
GET /dinosaurs/_search?q=name:Velocyraptor
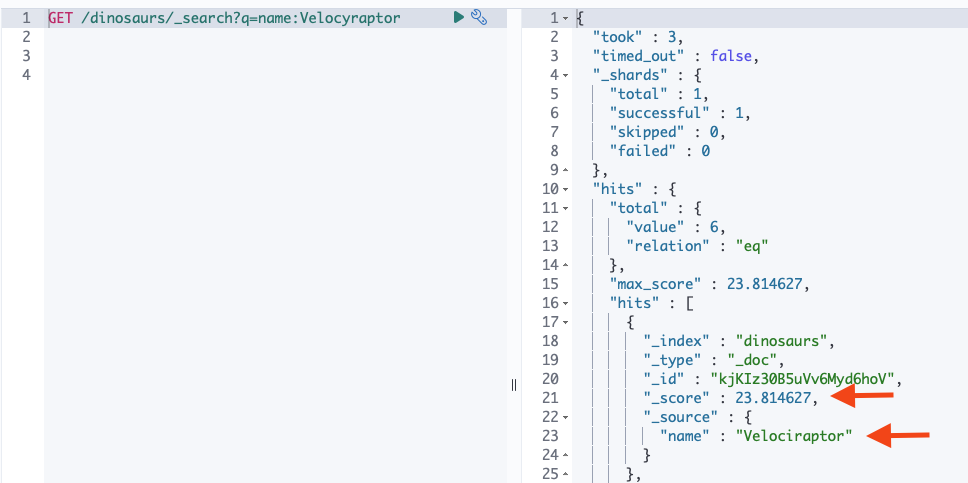
Now several results are displayed. The hits are weighted (hit score) according to importance.